
Annotation
This article is a follow up to Part 1 of Tarteel’s ML Journey, Data Collection. If you haven’t read it, you can do so here and then come back!
Data is the new oil. If your model doesn’t have a clean and varied dataset for training, it’s not going to perform at its peak.
As the saying goes: garbage in, garbage out.
In this section, we'll walk through the steps we took to clean up our audio data and annotate it, explaining the reasoning and insights behind each decision. We'll also discuss the lessons learned and why this approach ensures accuracy and effectiveness throughout the process.
Approach
During the process of crowdsourcing our audio data, we realized that some of the recordings might not be completely accurate or may have issues with their labelling and recording. To bootstrap our annotation process, we took the same crowdsourcing approach for evaluating audio files, copying a similar interface to the Mozilla Common Voice project.
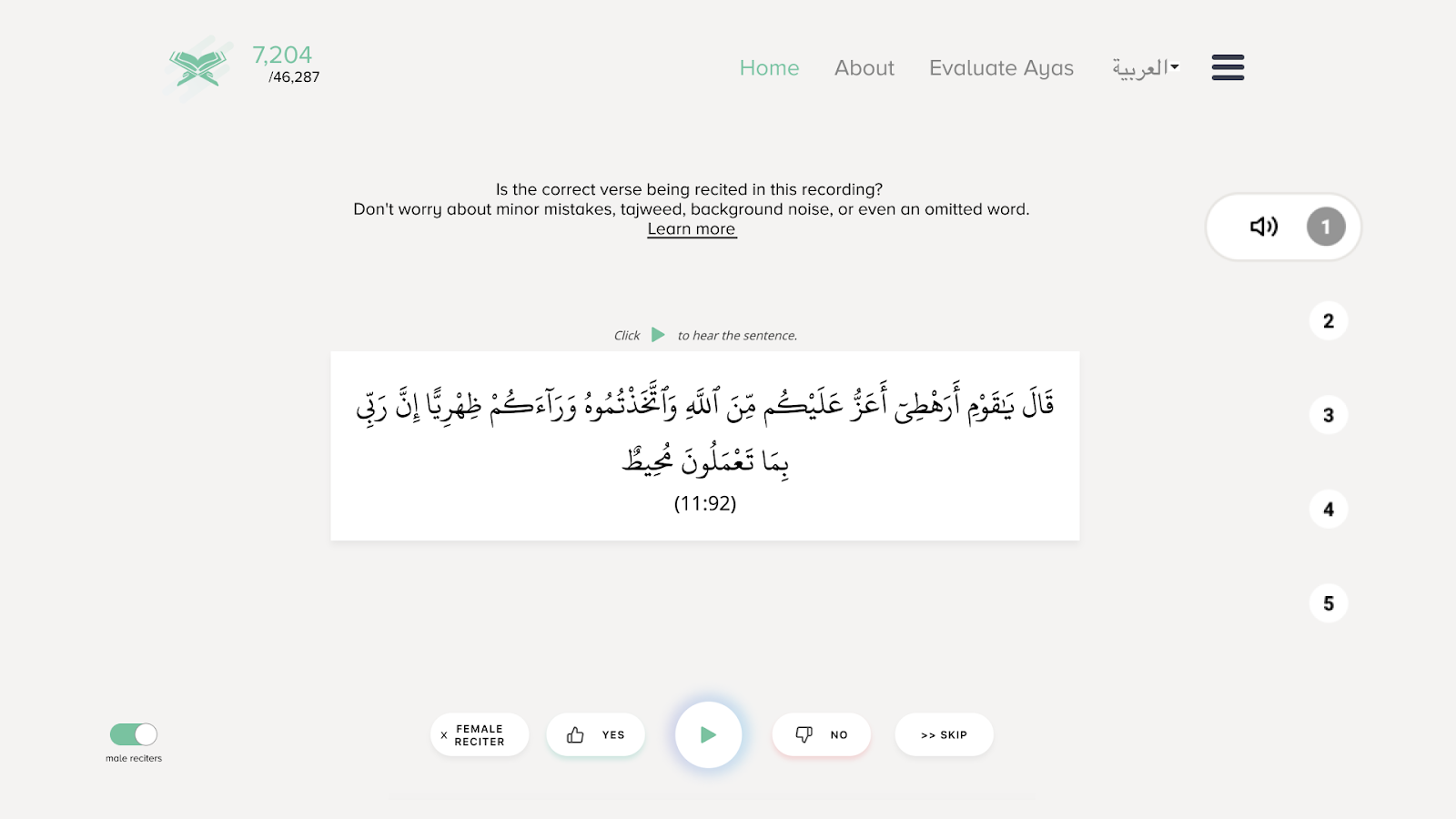
In this interface, all annotators had to do was select “Yes” or “No” to confirm if the recording matched the verse it was associated with. At this point, there wasn’t any vetting of annotators or extensive validation to confirm if the entire verse was recited correctly or incorrectly.
We attempted to respect the privacy of female reciters by filtering them from the dataset using a simple classifier model. However, this approach was unsuccessful because we hadn’t originally labeled the audio by gender. Attempts to use pre-built models also failed, and with limited resources, we chose not to pursue this feature at this time.
Many of our recordings were eventually labeled, but we overfitted our data model too tightly to the domain, making it hard to evaluate results and limiting the diversity of the recordings. We restricted both recordings and labels to specific verses, which allowed us to build a verse classifier, but not a speech recognition model. Furthermore, incorrect recitations with improper tashkeel couldn’t be flagged due to the limitations of the interface.
Since our initial goal was to just “ship fast” and collect as much data as possible, we realized most of this after the fact and while it resulted in countless learnings, the process also rendered a lot of our annotation efforts moot and required us to re-architect the whole pipeline from scratch.
Finding the right annotators
We realized that if we wanted to build a quality speech recognition model, we had to first source high quality annotations, carried by reliable individuals.
You can’t Mechanical Turk your way with labelling Quran recitations; not everyone understands Arabic and even fewer are capable of understanding and correcting Quran recitation.
Crowdsourcing
We initially took the same approach as before—building a community of annotators. Crowdsourcing can be an efficient way to get many hands on deck quickly, but it demands significant management to ensure proper Quranic annotation.
We used Airtable to onboard people, testing their skills with sample files. Those who passed moved on to training, while others were cut. However, the sheer volume of applicants overwhelmed us, and managing the process became unsustainable, akin to a full-time hiring role. We thought we could cut costs with crowdsourcing, but we were wasting our most precious resource, time, with little to show for it.
Realizing this, we opted to explore outsourcing the data annotation team instead.
Third Party Annotation Companies
We reached out to our network of engineers and founders to learn which companies were being used to annotate data, specifically with experience in Arabic. We were surprised to find a decent amount of speciality/boutique firms specifically catered towards data annotation tasks related to the MENA region.
One firm we found for example, hired mainly women in regions where they might not have an opportunity to work, came from Arab or Arabic speaking backgrounds, and were familiar with the Quran. This made said firm almost the perfect company to outsource our data annotation to!
The main problem was cost: while they took care of a lot of the overhead, using a third-party company involved a premium that we did not have the financial means for (at the time). And so we continued to explore alternative options.
In-House Contractors
We continued pressing our network for more options until we were connected directly with an individual whose primary expertise is managing teams of annotators, specifically in Egypt.
We brought this individual on board as a contractor and leveraged his network to recruit annotators as subcontractors. He adopted our onboarding approach and identified 50 qualified annotators. The results exceeded our expectations—the team was able to annotate over 500 hours of data per month with impressive quality, even adding Tashkeel annotations!
By finding and hiring the right person to manage one of the most important parts of our ML stack, it allowed us to focus on delivering value to our users instead. A lesson that can be applied to almost any startup!
Finding the right platform
While we were looking for an annotation team, I personally was also exploring the “how” of annotation. You can have a stellar team, but if you don’t give them the right tools, you’re setting them up for failure. We explored many tools and worked with a handful of them for quite some time, but eventually we chose Retool.
Custom 3rd Party Platforms
We initially believed that finding a custom platform would provide the best solution while being cost-effective. We evaluated several tools like LabelBox and Figure8, as well as others tailored for Arabic ML tasks in the GCC. However, we found these platforms lacking in necessary features and challenging to onboard or work with. Most were designed for image and text-based tasks, not audio, limiting their suitability for our project.

LabelStudio
Some extensive Google-fu led us to LabelStudio, an open source platform with a paid enterprise offering. LabelStudio turned out to be a highly flexible and effective tool, offering great adaptability for our needs, especially since we could host it internally on our own infrastructure. There were some quirks, but the free solution met our annotation use case almost perfectly.
The main issue was that with the free offering, there were no RBAC policies, so all users had access to all annotations including those of others, meaning someone could come in, change everyone’s annotation, and sabotage the whole project.
While we didn’t have any malicious actors, it was somewhat difficult to connect LabelStudio with our own annotations and backend. The documentation for building integrations was lacking and after diving into the source code we realized there were many limitations that prevented us from scaling and managing our annotators.
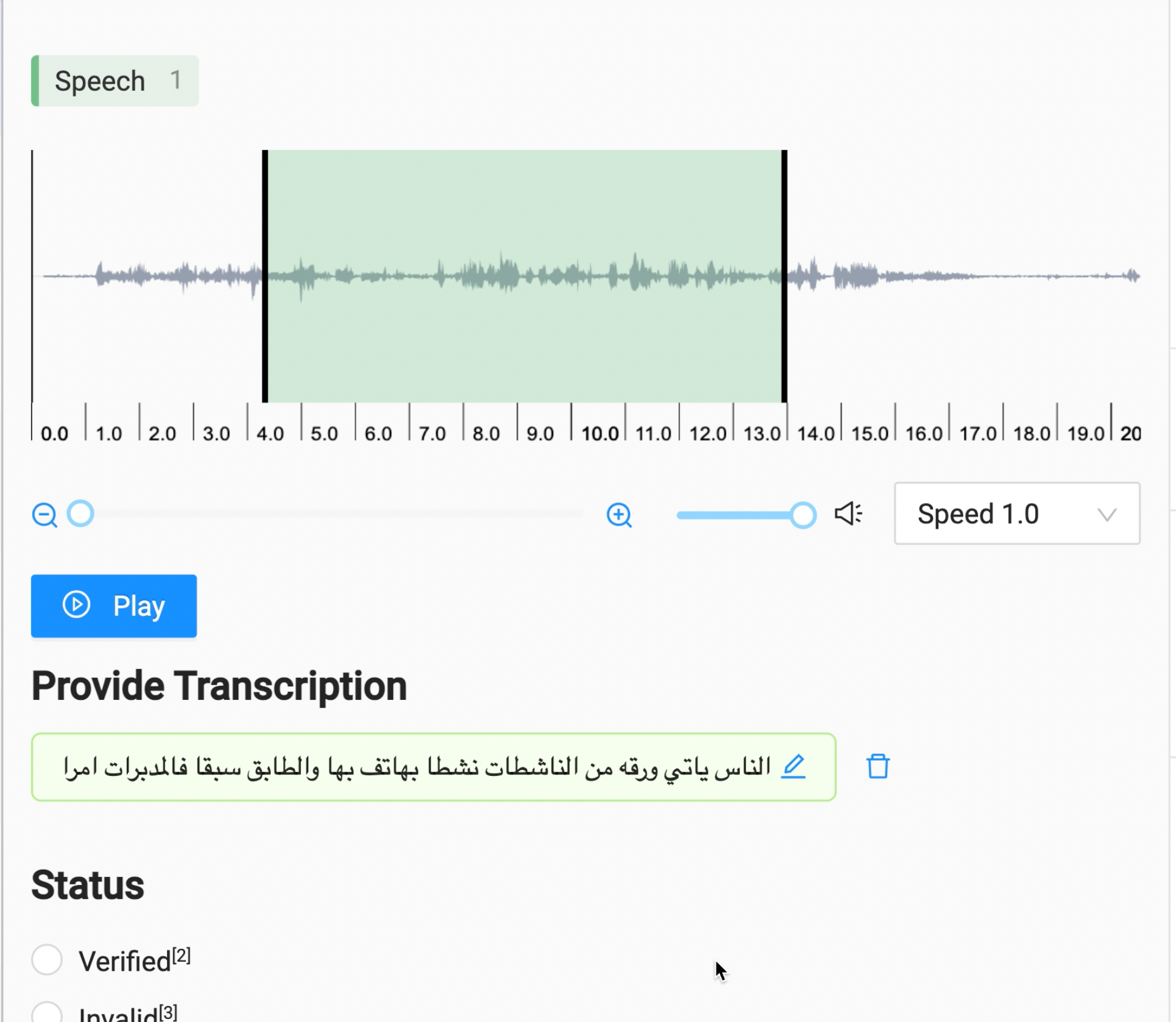
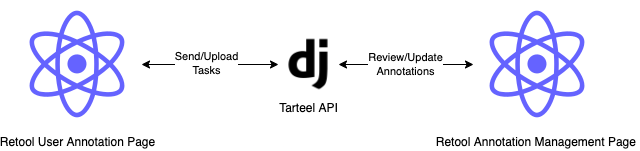
While most of this would be resolved with their enterprise offering, the pricing based on the number of users was cost-prohibitive. We really liked the UI however, and given that the code was open source, we decided to use LabelStudio in combination with Amazon GroundTruth, where LabelStudio was used to create a custom interface and GroundTruth was used to manage annotators and annotation “tasks”.
GroundTruth x LabelStudio
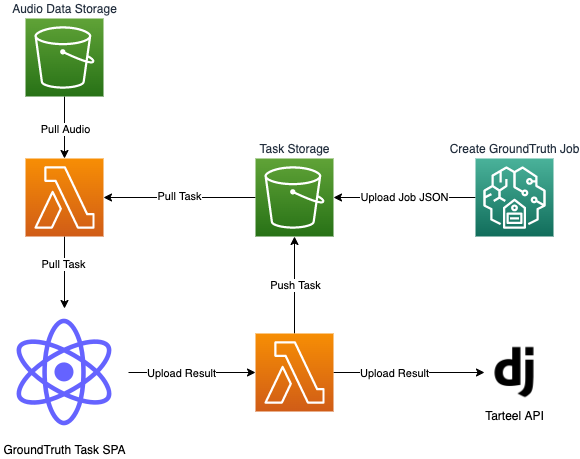
For a while, we used Amazon GroundTruth to create tasks and we wrote up a custom SPA with LabelStudio for the Task UI. In typical AWS fashion, GroundTruth was very complicated and the setup took a few days to write up and understand, involving some hacky JS and HTML workarounds, but in the end it worked out.
GroundTruth was great at what it did because it handled:
- Managing Individual Annotators
- Managing Teams of Annotators
- Authentication
- Individual task tracking
- Job/Batch tracking
But getting all this setup was a extremely difficult and cumbersome! There were multiple friction points. Here are a few:
Custom Lambdas
The first is that if you wanted to use your own custom interface, you had to write up a custom Lambda function to handle preparing the task and processing the submission.
While the docs provide you with some default code to work off of, it begs the question why this even needs to be done? Why can’t AWS provide sensible defaults to get a project up and running? We had to spend unnecessary time debugging permissions issues and running fake jobs to try and debug a Lambda function by dumping print statements everywhere. After copy-pasting different code recommendations from StackOverflow, we got things up and running.
Poor DX/UX
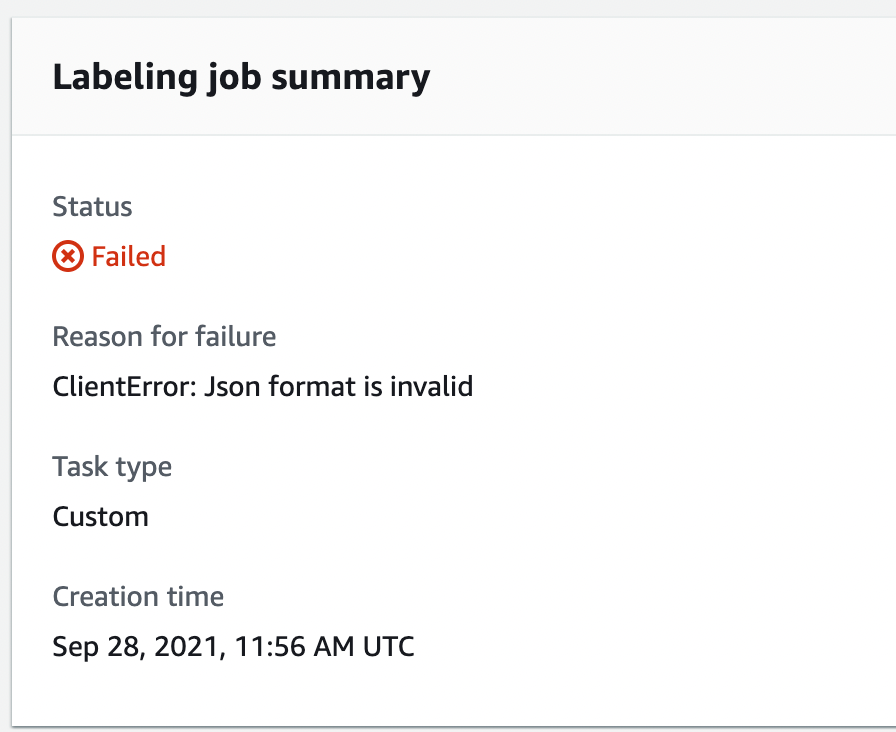
The second is that creating a labelling Job was a very delicate process. Every batch required a meticulously crafted JSON lines (.jsonl) file to be uploaded. If it had an extra white space somewhere or new line, it would cause the entire job to fail. There was no basic sanitization done from AWS’ end, nor were there any descriptive error messages about the problem with the file. Just “Json format is invalid”...
We decided to purchase AWS’ premium customer support tier. Debugging this with support took 2-3 weeks of back and forth only for them to finally inform us that we had to simply remove the whitespace from the end of a line.
Poor Management UX
The interface for managing annotators was far from user-friendly. Our annotations manager had to learn the AWS console and some basic English just to complete the simple task of adding or removing team members. We even had to create a step-by-step guide for him to follow. Requiring AWS knowledge for something as basic as annotator management in GroundTruth doesn’t make sense and adds unnecessary complexity.
Poor Job Summary
Lastly, there was way of viewing the results of a labelling job in a reasonable manner, nor could you associate tasks with annotators so you can see who did what and how much work they got down in order to review and improve their performance. We had to build our own record of annotators in our DB and manually link them using the custom Lambda functions mentioned earlier in this blog.
Building all this infra cost us two engineering weeks and would have cost us $9000/month if we didn’t have AWS credits. This was where we realized we need a custom solution.
Retool
When we first discovered Retool, it was initially to develop our annotation tool, but it quickly became our go-to platform for building all new internal tools and has proven to be an invaluable asset!
Within just a few days, we were able to create the labelling interface and connect it to our backend. Although the audio labelling and playback features weren’t as refined as LabelStudio's, Retool’s simplicity and ease of setup made it far more efficient to work with for our needs.
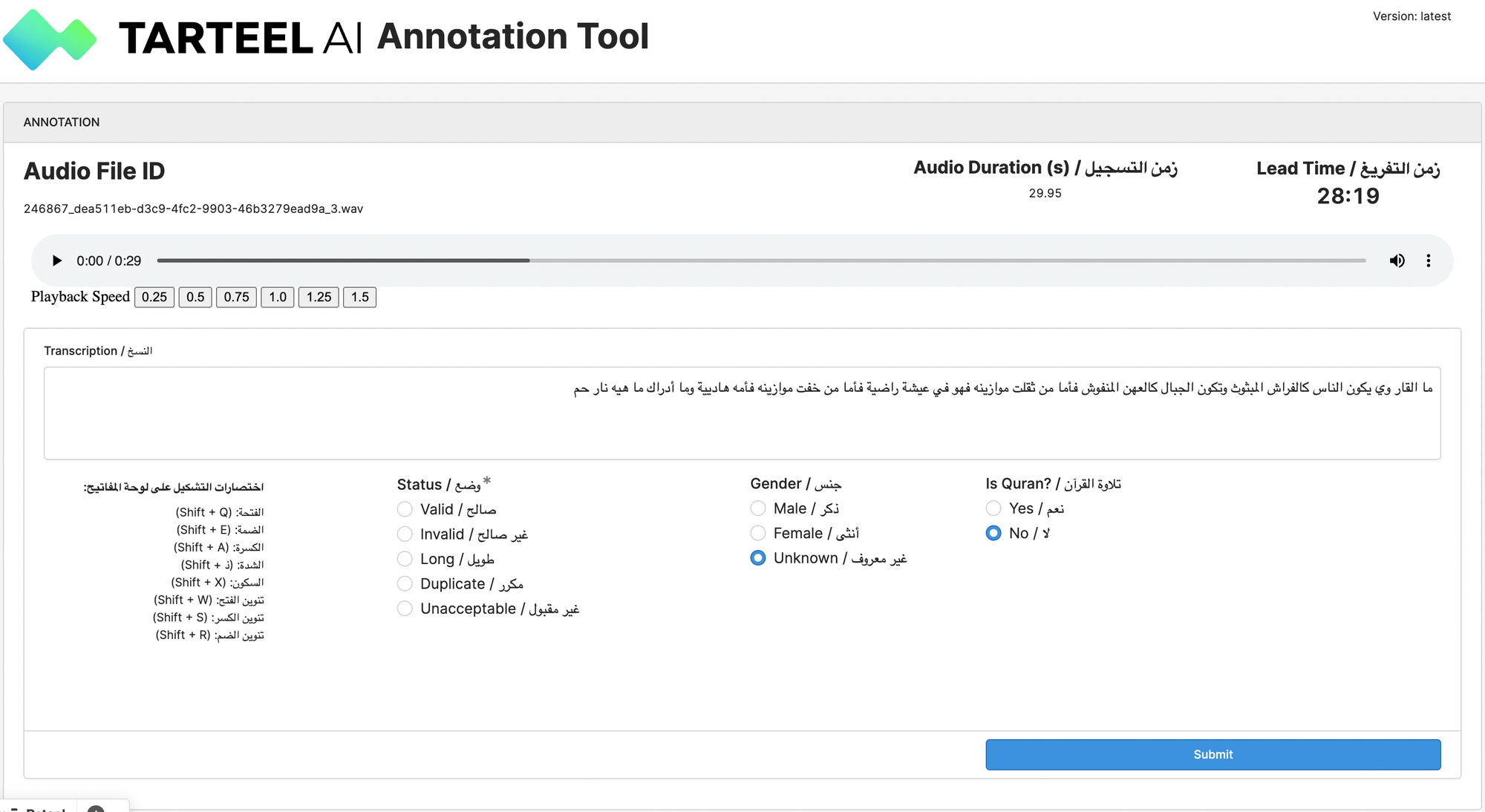
Our initial MVP was a basic interface, but as we refined it, we added nearly all of LabelStudio’s features, plus some tailored enhancements. These included tools to streamline annotators' workflows, such as allowing them to easily track their progress, and a custom dashboard for managers to review work, generate reports, and oversee productivity more effectively.
These improvements made the platform more robust and user-friendly, specifically designed to meet the needs of our annotation process.
We had some internal work to handle, but the investment proved well worth it. While third-party tools often make sense, none fit our specific use case. Building our solution on top of Retool was the right choice given our circumstances. Without Retool, we would have stuck with LabelStudio, as developing an entirely custom tool wouldn't have been practical. Retool’s flexibility bridged the gap between using an existing platform and creating something fully tailored to our needs.
Finding the right process
After all that setup and processing, we finally come to the last stage of annotation and that’s the “process.” There needed to be a pipeline for managing annotators and their work, including providing them with instructions and onboarding. While the annotation team manager handled most of the day-to-day issues and questions, we still had to set up the necessary instructions, documents, and workflows for new annotators and communicating changes.
What happens if we discover a certain rule that needs to be changed? What if we find an annotator performing poorly? How do we identify invalid/bad annotations? All of these will depend on your use case and is something you should write down and clarify to ensure the stability of your annotation workflow.
Data Pre-Processing
Once data has been annotated, the process towards training with a model needs to be streamlined. Different frameworks have different formats the training data, but they all generally cluster around JSON, Arrow, and/or CSVs. In our case, we mainly used JSON lines as a manifest for the audio file, where each line had the audio file path, label, and associated metadata.
Data Hosting and Download
Given that all the annotations are hosted in our database and audio files in S3, what’s the best way to make them accessible for training?
We wanted to minimize access to the database, so that when we created a new training dataset, we could run a Django management script that filters out the data we want and formats it into JSON lines (or any other format we specify). Generally, we don’t download the data when generating this particular file and leave that to take place during training time instead.
This is because we usually run training jobs on ephemeral instances and so it doesn’t make sense to move hundreds of GBs around from one instance to another. We recommend that you simply download on the instance you plan to train on.
The script also uploads the manifest to Weights and Biases (W&B) as a “Dataset Artefact”, which we then use and link in our training script. This helps us achieve model provenance, where we can identify which data was used to train which model.
Audio File Processing
Generally there isn’t much audio processing done at this stage since we’ve taken care of it during the data collection stage (from the start!)
If we do need to change things though, we usually just run ffmpeg in a script that looks like this:
# 1. Find all files in the input directory with the input file extension.
# 2. Convert each file to a specified sample frequency, specified number of channels, file type, etc.
# 3. Save the file in the specified output directory.
find ${input_dir} -type f -name '*.'${extension} -print0 | parallel --bar -0 ffmpeg -y -hide_banner -loglevel error -i {} -ar ${sampling_freq_hz} -ac ${num_channels} ${output_dir}'/'{.}.${new_extension}
Why use find and parallel? To speed up the process of course! Also, if you use ls to try and list and pipe the files, you’re likely going to run into an “Argument list too long” error, a limitation in Linux itself (See ARG_MAX for a more detailed discussion).
And there you have it! A sneak peek into our data annotation process and everything we learned along the way. Let us know what else you'd like to know about Tarteel's journey to being the World's Leading AI Quran Memorization Companion.



